本文文件下载
Advanced Data (高级数据)
glBufferSubData 及批处理
可以对已通过 glBufferData 创建的内存针对性写入. (这时候只用
glBufferData 创建内存, 传给它的数据可以是 NULL ).
glBufferSubData (GL_ARRAY_BUFFER, 24 , sizeof (data), &data);
先前使用的数据都是123123123这样子排列的,
比如顶点坐标-顶点法线-顶点纹理坐标. 可以通过 glBufferSubData 进行批处理,
使得数据呈现111222333这样的排列顺序.
float positions[] = { ... };float normals[] = { ... };float tex[] = { ... };glBufferSubData (GL_ARRAY_BUFFER, 0 , sizeof (positions), &positions);glBufferSubData (GL_ARRAY_BUFFER, sizeof (positions), sizeof (normals), &normals);glBufferSubData (GL_ARRAY_BUFFER, sizeof (positions) + sizeof (normals), sizeof (tex), &tex);
作为对比, 给出之前绘制 plane 时用到的部分代码.
float planeVertices[] = { ... };glGenVertexArrays (1 , &planeVAO);glGenBuffers (1 , &planeVBO);glBindVertexArray (planeVAO);glBindBuffer (GL_ARRAY_BUFFER, planeVBO);glBufferData (GL_ARRAY_BUFFER, sizeof (planeVertices), planeVertices, GL_STATIC_DRAW);
注意: 前者依旧需要 VAO, 以及 glBufferData 等等的操作, 二者的区别就是,
前者的 glBufferData 传递的 planeVertices 可以改成 NULL, 之后再接上三个
glBufferSubData. 两者在 glBufferData 的相同之处在于, 都使用
sizeof(planeVertices).
在为内存写入数据完毕后, 接下来指定 location 的代码也要更改.
glVertexAttribPointer (0 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof (float ), 0 ); glVertexAttribPointer (1 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof (float ), (void *)(sizeof (positions))); glVertexAttribPointer (2 , 2 , GL_FLOAT, GL_FALSE, 2 * sizeof (float ), (void *)(sizeof (positions) + sizeof (normals)));
还是比较好理解的. 就是直观地从123123123改成了111222333.
glMapBuffer
指定 buffer target, 返回绑定当前 target buffer 对应内存的指针.
float data[] = { 0.5f , 1.0f , -0.35f [...] }; glBindBuffer (GL_ARRAY_BUFFER, buffer);void *ptr = glMapBuffer (GL_ARRAY_BUFFER, GL_WRITE_ONLY);memcpy (ptr, data, sizeof (data));glUnmapBuffer (GL_ARRAY_BUFFER);
这段代码实现了将 data 的数据 copy 到 ptr 所指的 memory 中.
glCopyBufferSubData
及缓冲复制
直接给出prototype.
void glCopyBufferSubData (GLenum readtarget, GLenum writetarget, GLintptr readoffset, GLintptr writeoffset, GLsizeiptr size)
有一个问题就是, 我们无法同时为一个 buffer target 绑定两个 ID.
可以通过 GL_COPY_READ_BUFFER 和 GL_COPY_WRITE_BUFFER 完成同类型 buffer
target 之间的复制.
glBindBuffer (GL_COPY_READ_BUFFER, vbo1);glBindBuffer (GL_COPY_WRITE_BUFFER, vbo2);glCopyBufferSubData (GL_COPY_READ_BUFFER, GL_COPY_WRITE_BUFFER, 0 , 0 , 8 * sizeof (float ));
当然也可以只指定 write buffer.
float vertexData[] = { ... };glBindBuffer (GL_ARRAY_BUFFER, vbo1);glBindBuffer (GL_COPY_WRITE_BUFFER, vbo2);glCopyBufferSubData (GL_ARRAY_BUFFER, GL_COPY_WRITE_BUFFER, 0 , 0 , 8 * sizeof (float ));
Advanced GLSL (高级 GLSL)
GLSL 的内置变量
VERTEX SHADER
gl_PointSize : 在绘制点( GL_POINTS )而非三角形(
GL_TRIANGLE )或四边形时, 可以使用这个变量调整即将绘制的点的宽高.
这个变量仅在 vertex shader 中使用, 且需通过
glEnable(GL_PROGRAM_POINT_SIZE)启用. 在 vertex shader 中,
gl_PointSize 属于 output 变量
用例如下, 将 gl_PointSize 设置为当前点的深度值,
即可实现离远放大,接近缩小的效果.
void main () gl_Position = projection * view * model * vec4 (aPos, 1.0 ); gl_PointSize = gl_Position.z; }
gl_VertexID : 在 vertex shader 中使用, 属于 input
变量. 当启用 glDrawElements 时, 这个变量存储的是当前 vertex 的索引,
当启用 glDrawArrays 时, 存储的是当前渲染指令已处理的顶点个数.
FRAGMENT SHADER
gl_FragCoord : fragment shader 中的 input 变量,
存储的是当前 fragment 对应的四维坐标.
实际上就是经过一系列变换后得到的屏幕空间的坐标. 其 x, y 分量是当前
fragment 在屏幕上的二维坐标, z 分量是其深度值, 而 w 分量, 存储的是 1 /
w, 可以用于透视校正(来源 deepseek).
注意: gl_FragCoord 是个只读变量. 如果希望改变深度值, 需要使用
gl_FragDepth.
gl_FrontFacing : fragment shader 中的 input 变量.
这个变量会返回当前 fragment 是否正面朝向观察者(是个 bool 值).
通过这个变量, 可以实现物体表面和背面绘制不同的纹理.
gl_FragDepth : fragment shader 中的 output 变量,
用于设置当前 fragment 的深度值. 然而,
使用这个变量将导致提前深度测试被禁用. 除非使用
layout (depth_<condition>) out float gl_FragDepth;
显式指定对 gl_FragDepth 的操作条件. 这里的 depth condition 有四种:
Condition
Description
any
The default value. Early depth testing is disabled.
greater
You can only make the depth value larger compared to
gl_FragCoord.z.
less
You can only make the depth value smaller compared to
gl_FragCoord.z.
unchanged
If you write to gl_FragDepth, you will write exactly
gl_FragCoord.z.
第四种 unchanged 按我个人的理解是类似 const 变量,
也就是不让程序员修改当前 fragment 的深度值.
Interface blocks (接口块)
类似 struct 结构体, 只是将 shader 中的 in 和 out
变量改为结构体的形式. 代码大概长这样:
out VS_OUT { vec2 TexCoords; } vs_out; void main () gl_Position = projection * view * model * vec4 (aPos, 1.0 ); vs_out.TexCoords = aTexCoords; } in VS_OUT { vec2 TexCoords; } fs_in; void main () FragColor = texture (texture, fs_in.TexCoords); }
要求接口块名称相同, 但是由接口块创建的变量名字随意. 同时,
最好在接口块声明完毕后立刻接上变量的创建, 这一点也是符合 cpp 的 struct
语法的.
简单来说, 通过 ubo, 可以将之前见到的 uniform 变量从针对一个 shader
拓展到可以针对多个 shader. 一个重要的应用场景就是我们的 projection 和
view 矩阵.
在 shader 中, 需要使用 uniform block
指定我们想拓展的 uniform 变量
layout (std140) uniform Matrices{ mat4 projection; mat4 view; };
第二点就是在声明 uniform block 时, 使用 layout 指定的"数据存储形式".
这里使用的是 std140. 实际上还有其他的类型, 但这里不做拓展. 使用 std140,
为的是能够方便我们明确数据存储形式,
而其他类型会根据硬件或软件等方面的因素对数据类型的存储形式进行优化,
是好事, 但对我们来说并不方便. std140 并不是一个性能最优的方案,
但是胜在方便.
在一个 uniform block 中, 我们需要知道每个变量的 base alignment
(基准对齐量)和 aligned offset(对齐偏移量). 通俗地讲:
前者是指一个数据(包括补丁)所占的内存大小, 而后者就是这个数据在 uniform
block 中的偏移量, 并且这个偏移量必须是其 base alignment 的倍数.
这里给出部分类型对应的 layout rule. 每 4 个 bytes 对应一个 N.
Type
Layout rule
Scalar e.g. int or bool
Each scalar has a base alignment of N.
Vector
Either 2N or 4N. This means that a vec3 has a base alignment of
4N.
Array of scalars or vectors
Each element has a base alignment equal to that of a vec4.
Matrices
Stored as a large array of column vectors, where each of those
vectors has a base alignment of vec4.
Struct
Equal to the computed size of its elements according to the previous
rules, but padded to a multiple of the size of a vec4.
这里给出一个例子, 按照上表计算了对应的 base alignment 和 aligned
offset
layout (std140) uniform ExampleBlock{ float value; vec3 vector; mat4 matrix; float values[3 ]; bool boolean; int integer; };
以我们刚刚创建的 Matrix 结构体为例, 接下来我们要做的操作就是:
在主程序中为我们的 ubo 创建一块内存, 然后将数据传给 ubo. 最后, 我们会将
Matrix 和 ubo 绑定到同一个绑定点( binding point ) 上,
这样 shader 就会自己调用 ubo 中的数据.
首先, 创建 ubo. (这里的 152 对应上面我们举例所创建的 uniform
block)
unsigned int uboExampleBlock;glGenBuffers (1 , &uboExampleBlock);glBindBuffer (GL_UNIFORM_BUFFER, uboExampleBlock);glBufferData (GL_UNIFORM_BUFFER, 152 , NULL , GL_STATIC_DRAW); glBindBuffer (GL_UNIFORM_BUFFER, 0 );
然后, 查询我们 uniform block 的 index, 将其绑定到某个绑定点.
操作流程大致如下:
unsigned int lights_index = glGetUniformBlockIndex (shaderA.ID, "Lights" ); glUniformBlockBinding (shaderA.ID, lights_index, 2 );
大概意思就是: 获取 shaderA 中 Lights 结构体的 index, 然后用这个 index
将 Lights 结构体与绑定点 2 相绑定.
注: 绑定点的索引从 0 开始.
注: 在 OpenGl 4.2 以上的版本中, 可以直接在声明 uniform block
的时候使用 layout 指定绑定点, 从而省略这一步.
layout (std140, binding = 2 ) uniform Lights { ... };
我们也要让 ubo 绑定到相同的绑定点.
glBindBufferBase (GL_UNIFORM_BUFFER, 2 , uboExampleBlock); glBindBufferRange (GL_UNIFORM_BUFFER, 2 , uboExampleBlock, 0 , 152 );
注意: 也可以使用glBufferSubData, 指定 ubo
的子集绑定至该绑定点. 这个操作可以实现一个多个 uniform block 使用同一个
ubo.
具体到我们的应用场景, 对 projection 和 view 矩阵使用 uniform block,
给出代码实现.
#version 330 core layout (location = 0 ) in vec3 aPos;layout (std140) uniform Matrices{ mat4 projection; mat4 view; }; uniform mat4 model; void main () gl_Position = projection * view * model * vec4 (aPos, 1.0 ); } unsigned int uniformBlockIndexRed = glGetUniformBlockIndex (shaderRed.ID, "Matrices" );unsigned int uniformBlockIndexGreen = glGetUniformBlockIndex (shaderGreen.ID, "Matrices" );unsigned int uniformBlockIndexBlue = glGetUniformBlockIndex (shaderBlue.ID, "Matrices" );unsigned int uniformBlockIndexYellow = glGetUniformBlockIndex (shaderYellow.ID, "Matrices" ); glUniformBlockBinding (shaderRed.ID, uniformBlockIndexRed, 0 );glUniformBlockBinding (shaderGreen.ID, uniformBlockIndexGreen, 0 );glUniformBlockBinding (shaderBlue.ID, uniformBlockIndexBlue, 0 );glUniformBlockBinding (shaderYellow.ID, uniformBlockIndexYellow, 0 );unsigned int uboMatricesglGenBuffers (1 , &uboMatrices) glBindBuffer (GL_UNIFORM_BUFFER, uboMatrices);glBufferData (GL_UNIFORM_BUFFER, 2 * sizeof (glm::mat4), NULL , GL_STATIC_DRAW);glBindBuffer (GL_UNIFORM_BUFFER, 0 );glBindBufferRange (GL_UNIFORM_BUFFER, 0 , uboMatrices, 0 , 2 * sizeof (glm::mat4));glm::mat4 projection = glm::perspective (glm::radians (45.0f ), (float )width/(float )height, 0.1f , 100.0f ); glm::mat4 view = camera.GetViewMatrix (); glBindBuffer (GL_UNIFORM_BUFFER, uboMatrices);glBufferSubData (GL_UNIFORM_BUFFER, 0 , sizeof (glm::mat4), glm::value_ptr (projection));glBufferSubData (GL_UNIFORM_BUFFER, sizeof (glm::mat4), sizeof (glm::mat4), glm::value_ptr (view));glBindBuffer (GL_UNIFORM_BUFFER, 0 );
最后提一嘴, ubo 的优点在于, 不用每一帧都重新为每一个 shader 设定
uniform 值. 只需要每一帧改变 ubo 内的数据即可.
有个大坑需要注意: 不要觉得做了一次这个操作之后就可以不管了.
如果数据更新了(比如进入了 camera mode), 那么需要重新使用 glBufferSubData
来拷贝数据. 也因此我觉得这个功能并非那么好用. 实际上只要写一个统一更新
uniform 的函数, 每个物体绘制的时候都调用一次, 似乎更简洁明了.
不过转念一想也不是这样. 每一帧都更新不同 shader 的 uniform,
会增加函数调用的次数, 而且 cpu 与 gpu 之间的传输速度也是有限制的. emmm
那还是用 uniform block 吧...
另外一个大坑是: struct 结构体大小必须是 16 的整数倍.
因此必须在结构体内打非常多的padding.
实践后的反思
在自己写的渲染器中, 我将所有光照的参数都写成 uniform block 传给
fragment shader 了, 由于涉及的参数非常非常多, 我尝试过在 fragment shader
中根据类型来声明不同结构体的光源, 最后对每个光源种类创建对应的变量, 作为
uniform block 中的变量. 具体来说, 如下代码所示:
layout (std140) uniform Lights{ DirLight dirLight; PointLight pointLight; SpotLight spotLight; };
然后我根据前面的计算规则来传对应的参数, 如下:
if (RenderState::haveColor) { unsigned int uniformBlockIndex = glGetUniformBlockIndex (shader.ID, "Lights" ); glUniformBlockBinding (shader.ID, uniformBlockIndex, 1 ); static unsigned int uboLight; glGenBuffers (1 , &uboLight); glBindBuffer (GL_UNIFORM_BUFFER, uboLight); glBufferData (GL_UNIFORM_BUFFER, 224 , NULL , GL_STATIC_DRAW); glBindBufferRange (GL_UNIFORM_BUFFER, 1 , uboLight, 0 , 224 ); glBufferSubData (GL_UNIFORM_BUFFER, 0 , 4 , &Light::allLights[0 ]->open); if (Light::allLights[0 ]->open) { glBufferSubData (GL_UNIFORM_BUFFER, 16 , 16 , &Light::allLights[0 ]->direction); glBufferSubData (GL_UNIFORM_BUFFER, 32 , 16 , &Light::allLights[0 ]->color); glBufferSubData (GL_UNIFORM_BUFFER, 48 , 4 , &Light::allLights[0 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 52 , 4 , &Light::allLights[0 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 56 , 4 , &Light::allLights[0 ]->diffuseStrength); } glBufferSubData (GL_UNIFORM_BUFFER, 64 , 4 , &Light::allLights[1 ]->open); if (Light::allLights[1 ]->open) { glBufferSubData (GL_UNIFORM_BUFFER, 80 , 16 , &Light::allLights[1 ]->position); glBufferSubData (GL_UNIFORM_BUFFER, 96 , 16 , &Light::allLights[1 ]->color); glBufferSubData (GL_UNIFORM_BUFFER, 112 , 4 , &Light::allLights[1 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 116 , 4 , &Light::allLights[1 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 120 , 4 , &Light::allLights[1 ]->diffuseStrength); } glBufferSubData (GL_UNIFORM_BUFFER, 128 , 4 , &Light::allLights[2 ]->open); if (Light::allLights[2 ]->open) { glBufferSubData (GL_UNIFORM_BUFFER, 144 , 16 , &Light::allLights[2 ]->position); glBufferSubData (GL_UNIFORM_BUFFER, 160 , 16 , &Light::allLights[2 ]->direction); static float cutoff = 0 ; cutoff = glm::cos (glm::radians (Light::allLights[2 ]->cutoff)); static float outerCutoff = 0 ; outerCutoff = glm::cos (glm::radians (Light::allLights[2 ]->cutoff + 5.0f )); glBufferSubData (GL_UNIFORM_BUFFER, 176 , 4 , &cutoff); glBufferSubData (GL_UNIFORM_BUFFER, 180 , 4 , &outerCutoff); glBufferSubData (GL_UNIFORM_BUFFER, 192 , 16 , &Light::allLights[2 ]->color); glBufferSubData (GL_UNIFORM_BUFFER, 208 , 4 , &Light::allLights[2 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 212 , 4 , &Light::allLights[2 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 216 , 4 , &Light::allLights[2 ]->diffuseStrength); } glBindBuffer (GL_UNIFORM_BUFFER, 0 ); }
结果就是渲染结果出现错误. 经过测试, 直到 directional light
的最后一个参数 diffuse strength 之前都是正常的, 之后的都出错了.
只能说如果不查阅 wiki 彻底搞明白其内存存储形式的话, 这样做似乎比较困难.
在尝试了一整个上午后, 以失败告终.
但是由于 projection 和 view 矩阵的实践是比较顺利的,
我就尝试直接将三个种类的光源写成三个 uniform block, 并且根据先前创建
Matrix 一样的形式来写, 最后成功了, 但也有一些要注意的点,
可以先看代码.
layout (std140) uniform DirLight{ bool DirOpen; float DirAmbientStrength; float DirSpecularStrength; float DirDiffuseStrength; vec3 DirDirection; vec3 DirLightCol; }; layout (std140) uniform PointLight{ bool PointOpen; float PointAmbientStrength; float PointSpecularStrength; float PointDiffuseStrength; vec3 PointPosition; vec3 PointLightCol; }; layout (std140) uniform SpotLight{ bool SpotOpen; float SpotAmbientStrength; float SpotSpecularStrength; float SpotDiffuseStrength; float SpotCutOff; float SpotOuterCutOff; vec3 SpotPosition; vec3 SpotDirection; vec3 SpotLightCol; }; void Draw::updateUniform () static unsigned int uboMat = 0 ; static unsigned int uboDirLight = 0 ; static unsigned int uboPointLight = 0 ; static unsigned int uboSpotLight = 0 ; if (uboMat == 0 ) { glGenBuffers (1 , &uboMat); glBindBuffer (GL_UNIFORM_BUFFER, uboMat); glBufferData (GL_UNIFORM_BUFFER, 2 * sizeof (glm::mat4), NULL , GL_STATIC_DRAW); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); glBindBufferRange (GL_UNIFORM_BUFFER, 0 , uboMat, 0 , 2 * sizeof (glm::mat4)); } glBindBuffer (GL_UNIFORM_BUFFER, uboMat); glBufferSubData (GL_UNIFORM_BUFFER, 0 , sizeof (glm::mat4), glm::value_ptr (RenderState::view)); glBufferSubData (GL_UNIFORM_BUFFER, sizeof (glm::mat4), sizeof (glm::mat4), glm::value_ptr (RenderState::projection)); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); if (uboDirLight == 0 ) { glGenBuffers (1 , &uboDirLight); glBindBuffer (GL_UNIFORM_BUFFER, uboDirLight); glBufferData (GL_UNIFORM_BUFFER, 48 , NULL , GL_STATIC_DRAW); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); glBindBufferRange (GL_UNIFORM_BUFFER, 1 , uboDirLight, 0 , 48 ); } glBindBuffer (GL_UNIFORM_BUFFER, uboDirLight); glBufferSubData (GL_UNIFORM_BUFFER, 0 , 4 , &Light::allLights[0 ]->open); glBufferSubData (GL_UNIFORM_BUFFER, 4 , 4 , &Light::allLights[0 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 8 , 4 , &Light::allLights[0 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 12 , 4 , &Light::allLights[0 ]->diffuseStrength); glBufferSubData (GL_UNIFORM_BUFFER, 16 , 16 , &Light::allLights[0 ]->direction); glBufferSubData (GL_UNIFORM_BUFFER, 32 , 16 , &Light::allLights[0 ]->color); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); if (uboPointLight == 0 ) { glGenBuffers (1 , &uboPointLight); glBindBuffer (GL_UNIFORM_BUFFER, uboPointLight); glBufferData (GL_UNIFORM_BUFFER, 48 , NULL , GL_STATIC_DRAW); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); glBindBufferRange (GL_UNIFORM_BUFFER, 2 , uboPointLight, 0 , 48 ); } glBindBuffer (GL_UNIFORM_BUFFER, uboPointLight); glBufferSubData (GL_UNIFORM_BUFFER, 0 , 4 , &Light::allLights[1 ]->open); glBufferSubData (GL_UNIFORM_BUFFER, 4 , 4 , &Light::allLights[1 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 8 , 4 , &Light::allLights[1 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 12 , 4 , &Light::allLights[1 ]->diffuseStrength); glBufferSubData (GL_UNIFORM_BUFFER, 16 , 16 , &Light::allLights[1 ]->position); glBufferSubData (GL_UNIFORM_BUFFER, 32 , 16 , &Light::allLights[1 ]->color); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); if (uboSpotLight == 0 ) { glGenBuffers (1 , &uboSpotLight); glBindBuffer (GL_UNIFORM_BUFFER, uboSpotLight); glBufferData (GL_UNIFORM_BUFFER, 80 , NULL , GL_STATIC_DRAW); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); glBindBufferRange (GL_UNIFORM_BUFFER, 3 , uboSpotLight, 0 , 80 ); } static float cutoff = 0 ; cutoff = glm::cos (glm::radians (Light::allLights[2 ]->cutoff)); static float outerCutoff = 0 ; outerCutoff = glm::cos (glm::radians (Light::allLights[2 ]->cutoff + 5.0f )); glBindBuffer (GL_UNIFORM_BUFFER, uboSpotLight); glBufferSubData (GL_UNIFORM_BUFFER, 0 , 4 , &Light::allLights[2 ]->open); glBufferSubData (GL_UNIFORM_BUFFER, 4 , 4 , &Light::allLights[2 ]->ambientStrength); glBufferSubData (GL_UNIFORM_BUFFER, 8 , 4 , &Light::allLights[2 ]->specularStrength); glBufferSubData (GL_UNIFORM_BUFFER, 12 , 4 , &Light::allLights[2 ]->diffuseStrength); glBufferSubData (GL_UNIFORM_BUFFER, 16 , 4 , &cutoff); glBufferSubData (GL_UNIFORM_BUFFER, 20 , 4 , &outerCutoff); glBufferSubData (GL_UNIFORM_BUFFER, 32 , 16 , &Light::allLights[2 ]->position); glBufferSubData (GL_UNIFORM_BUFFER, 48 , 16 , &Light::allLights[2 ]->direction); glBufferSubData (GL_UNIFORM_BUFFER, 64 , 16 , &Light::allLights[2 ]->color); glBindBuffer (GL_UNIFORM_BUFFER, 0 ); }
思路上代码依旧还是比较直观的. 需要注意的就是, 最好将 uniform block
中的变量按照从小到大的顺序来排列. 可以发现我是从 float 到 vec3
这样的顺序声明 uniform block 的, 这样做也是经过实验得到的经验. 如果将
float 和 vec3 穿插着写, 最后依旧会出现错误, 即使我已经完全按照
learnOpenGL 中给出的计算规则来写.
Geometry Shader (几何着色器)
概述
geometry shader 处于 vertex shader 之后, fragment shader 之前,
可以用来处理 vertex shader 输出的顶点. 一个典型的 geometry shader
大概如下
#version 330 core layout (points) in;layout (line_strip, max_vertices = 2 ) out;void main () gl_Position = gl_in[0 ].gl_Position + vec4 (-0.1 , 0.0 , 0.0 , 0.0 ); EmitVertex (); gl_Position = gl_in[0 ].gl_Position + vec4 ( 0.1 , 0.0 , 0.0 , 0.0 ); EmitVertex (); EndPrimitive (); }
先对 vertex shader 的输出, 也就是 "in", 指定好类型.
这取决于我们在使用 glDrawArrays 的时候选择的是什么.
points: when drawing GL_POINTS primitives (1).
lines: when drawing GL_LINES or GL_LINE_STRIP (2).
lines_adjacency: GL_LINES_ADJACENCY or
GL_LINE_STRIP_ADJACENCY (4).
triangles: GL_TRIANGLES, GL_TRIANGLE_STRIP or
GL_TRIANGLE_FAN (3).
triangles_adjacency: GL_TRIANGLES_ADJACENCY or
GL_TRIANGLE_STRIP_ADJACENCY (6).
注: 小括号内的数字代表该 primitive 所需的最少的顶点数.
接着对 geometry shader 的输出指定好类型, 最大顶点数.
layout (line_strip, max_vertices = 2 ) out;
points
line_strip
triangle_strip
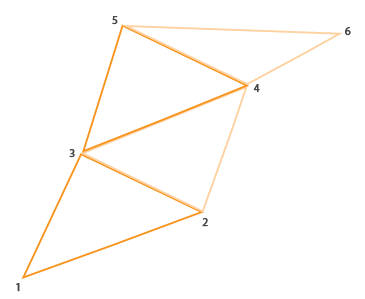
需要讲的就是 max_vertices 了. 首先指出, points 的 max_vertices 最少为
1, line_strip 至少为 2, triangle_strip 至少为 3. 其次就是这里的
max_vertices 是干嘛用的? 我的理解就是, 在 main 函数中将会创建几个点.
比如在本例, 将会使用一个 vertex shader 的输出创建两个点,
然后再用这两个点绘制一条线段. 在 learnOpenGL 中还给出了画房子的例子,
用五个点画出了三个三角形( 123, 234, 345 ), 它用的 max_vertices
就是5.
然后是 gl_in, 在此, gl_in 是一个数组, 存着由 vertex shader 输出的当前
primitive 的所有顶点. 比如使用的是 GL_TRIANGLE, 那么 gl_in
就存了三个顶点. 其内部结构如下
in gl_Vertex { vec4 gl_Position; float gl_PointSize; float gl_ClipDistance[]; } gl_in[];
至此我们的 main 函数就比较好看懂了. 每计算好一个点的位置, 就
EmitVertex();一下, 在本例中, 每 EmitVertex()
一次, 就代表生成两个点, 程序就会自动生成一条线段. 最后使用
EndPrimitive(); 结束.
应用
geometry shader 需要像其他 shader 那样, 链接到一个 shader 程序中.
geometryShader = glCreateShader (GL_GEOMETRY_SHADER); glShaderSource (geometryShader, 1 , &gShaderCode, NULL );glCompileShader (geometryShader); [...] glAttachShader (program, geometryShader);glLinkProgram (program);
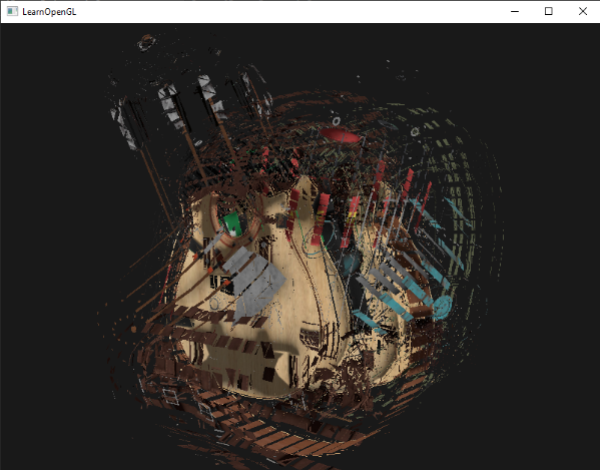
在 geometry shader 中绘制三角形, 大概如下
explosion
通过 gl_in 中存储的顶点使用叉乘, 可以得到当前面的法向量,
让所有顶点沿着法线方向前进一段距离, 就可以实现explode效果.
#version 330 core layout (triangles) in;layout (triangle_strip, max_vertices = 3 ) out;in VS_OUT { vec2 texCoords; } gs_in[]; out vec2 TexCoords; uniform float time; vec4 explode (vec4 position, vec3 normal) float magnitude = 2.0 ; vec3 direction = normal * ((sin (time) + 1.0 ) / 2.0 ) * magnitude; return position + vec4 (direction, 0.0 ); } vec3 GetNormal () vec3 a = vec3 (gl_in[0 ].gl_Position) - vec3 (gl_in[1 ].gl_Position); vec3 b = vec3 (gl_in[2 ].gl_Position) - vec3 (gl_in[1 ].gl_Position); return normalize (cross (a, b)); } void main () vec3 normal = GetNormal (); gl_Position = explode (gl_in[0 ].gl_Position, normal); TexCoords = gs_in[0 ].texCoords; EmitVertex (); gl_Position = explode (gl_in[1 ].gl_Position, normal); TexCoords = gs_in[1 ].texCoords; EmitVertex (); gl_Position = explode (gl_in[2 ].gl_Position, normal); TexCoords = gs_in[2 ].texCoords; EmitVertex (); EndPrimitive (); }
不过使用这个效果的成本还是挺高的, 或者说比较麻烦.
因为使用这个意味着我们需要另外创建一个 shader 程序, 让 vs, gs, fs 三者的
in 和 out 变量对应.
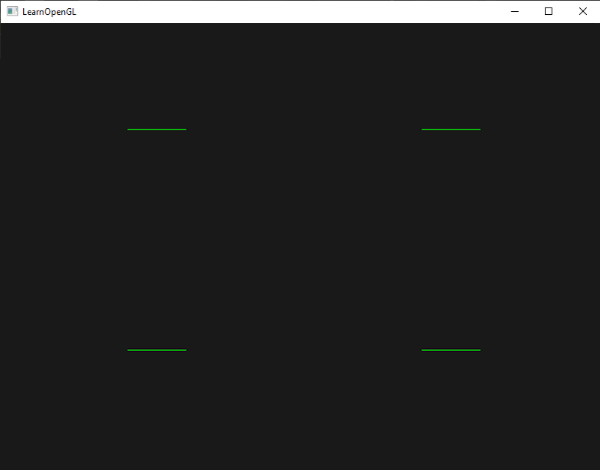
可视化法线
将法线信息也传给 geometry shader,
用当前顶点位置和从当前顶点位置向法线方向移动一段距离的位置创建两个点,
一个三角形三个顶点所以我们的 max_vertices = 6. 最后要在 fragment shader
中指定法线的颜色.
#version 330 core layout (triangles) in;layout (line_strip, max_vertices = 6 ) out;in VS_OUT { vec3 normal; } gs_in[]; const float MAGNITUDE = 0.4 ; uniform mat4 projection; void GenerateLine (int index) gl_Position = projection * gl_in[index].gl_Position; EmitVertex (); gl_Position = projection * (gl_in[index].gl_Position + vec4 (gs_in[index].normal, 0.0 ) * MAGNITUDE); EmitVertex (); EndPrimitive (); } void main () GenerateLine (0 ); GenerateLine (1 ); GenerateLine (2 ); }
记得在 view 空间下移动点的位置, 然后再乘 projection.
#version 330 core out vec4 FragColor; void main () FragColor = vec4 (1.0 , 1.0 , 0.0 , 1.0 ); }
法线可视化相比之下更加常用, 因为只需要额外加一个 shader,
而非切换.
实际上在学完之后还是有点不太通透的感觉(在 vs, gs, fs
三者参数传递方面). 理一下的话, 应该 fragment shader
绘制的是新创建的点形成的 primitive, 所以在绘制 explosion 的时候, gs
中每个点都要给定一个 texCoord, 然后再在 fs 中采样. 而对于法线可视化,
只需要用 normal 生成 顶点, 所以不需要额外传东西给 fs, 让 fs
正常画出这条直线即可. 嗯, 这样就通透了.
实践后的反思
用了整整一下午四五个小时的时间, 将 explosion 和
法线可视化整合到渲染器里了. 之前提到的很多问题都确实遇到了.
就是为了加一个 explosion, 是否需要重新专门写一个新的 vertex shader 和
fragment shader, 仅仅是因为 in 和 out 变量无法对应? 为了解决这个问题,
我大胆地试了两个方法: 在 gs 中让 out 变量和 in 变量同名, 以及让 fs 的 in
变量有两种, 通过 if 来使用不同的 in 变量. 结论是后者是正确的.
代码类似下面这样.
in VS_OUT { vec2 texCoord; vec3 worldPos; vec3 normal; } vs_out; in GS_OUT { vec2 texCoord; vec3 worldPos; vec3 normal; } gs_out; vec3 worldPos = vec3 (0.0 , 0.0 , 0.0 ); vec3 normal = vec3 (0.0 , 0.0 , 0.0 ); vec2 texCoord = vec2 (0.0 , 0.0 ); if (enableGeometryShader) { worldPos = gs_out.worldPos; normal = gs_out.normal; texCoord = gs_out.texCoord; } else { worldPos = vs_out.worldPos; normal = vs_out.normal; texCoord = vs_out.texCoord; }
第二点就是, 要注意 gs 的 out 变量是单个的, 而 in 变量是个数组.
in VS_OUT { vec2 texCoord; vec3 worldPos; vec3 normal; } gs_in[]; out GS_OUT{ vec2 texCoord; vec3 worldPos; vec3 normal; } gs_out;
最后就是, 要非常注意计算时所在的空间. 比如 explosion,
让物体位移时我们是直接在 gl_position 的基础上进行的, 但是由于我自己想给
explosion 之后的物体也计算光照, 所以我需要获取 explosion
之后物体各顶点在世界空间下的坐标以及法线(实际上法线不会改变,
因为顶点本身也是沿着法线移动), 因此就需要比较细致地了解 gs 与其他两个
shader 之间的数据传输情况.
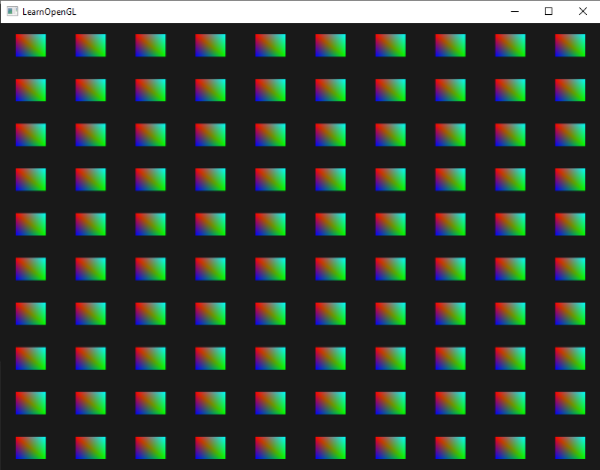
Instancing (实例化)
概述
实例化( instancing )一般用于绘制大量重复物体.
在绘制物体时, 最容易想到的渲染方法是:
for (unsigned int i = 0 ; i < amount_of_models_to_draw; i++){ DoSomePreparations (); glDrawArrays (GL_TRIANGLES, 0 , amount_of_vertices); }
这种最平常的方法的局限往往不在于渲染速度的快慢, 而在于渲染指令的多少.
使用 glDrawArrays, 不仅让 GPU 执行渲染,
也会执行如确认从哪个 buffer 读取数据, 从哪里寻找 vertex attribute 等等.
一旦 glDrawArrays 的数量一多,
这些指令的大量传输会严重影响表现.
实例化相比这种方式, 一个最大的改变就是使用
glDrawArraysInstanced 和
glDrawElementsInstanced, 仅使用一个 rendere call
就将绘制大量物体的指令传递给 GPU, 节约了大部分 CPU 和 GPU
之间数据传输的时间.
相比 glDrawArrays, glDrawArraysInstanced
多了一个参数, 即要绘制的 instance 的数量.
在 shader 中, 我们可以通过 gl_InstanceID
获取当前正在绘制的 instance 的 ID. 这个 ID 是从 0 开始索引的.
使用以上代码绘制一百个 quad, 部分关键代码如下:
glm::vec2 translations[100 ]; int index = 0 ;float offset = 0.1f ;for (int y = -10 ; y < 10 ; y += 2 ){ for (int x = -10 ; x < 10 ; x += 2 ) { glm::vec2 translation; translation.x = (float )x / 10.0f + offset; translation.y = (float )y / 10.0f + offset; translations[index++] = translation; } } shader.use (); for (unsigned int i = 0 ; i < 100 ; i++){ shader.setVec2 (("offsets[" + std::to_string (i) + "]" ), translations[i]); } glBindVertexArray (quadVAO);glDrawArraysInstanced (GL_TRIANGLES, 0 , 6 , 100 );
#version 330 core out vec4 FragColor; in vec3 fColor; void main () FragColor = vec4 (fColor, 1.0 ); } #version 330 core layout (location = 0 ) in vec2 aPos;layout (location = 1 ) in vec3 aColor;out vec3 fColor; uniform vec2 offsets[100 ]; void main () vec2 offset = offsets[gl_InstanceID]; gl_Position = vec4 (aPos + offset, 0.0 , 1.0 ); fColor = aColor; }
可以看到, 上面代码的大致思路就是: 在 cpp 文件中写一个 offset 数组,
然后传给 shader, 作为 uniform 给 shader 通过 gl_InstanceID 来获取数据.
不过这种方法依旧不是最优, 可能会因为 uniform 变量的数量上限而受限.
下面介绍另一种传递数据的方法: Instanced arrays .
Instanced arrays 也是一种 vertex attribute, 但它只在绘制每一个新
instance 时更新, 而非绘制每一个顶点时更新一次. ( 一个 instance
可能包含多个顶点, 对吗? )
在 shader 中这样写:
#version 330 core layout (location = 0 ) in vec2 aPos;layout (location = 1 ) in vec3 aColor;layout (location = 2 ) in vec2 aOffset;out vec3 fColor; void main () gl_Position = vec4 (aPos + aOffset, 0.0 , 1.0 ); fColor = aColor; }
看上去跟正常的 vertex attribute 没什么区别. 在 cpp
文件中也是正常地创建 VBO和 VAO.
unsigned int instanceVBO;glGenBuffers (1 , &instanceVBO);glBindBuffer (GL_ARRAY_BUFFER, instanceVBO);glBufferData (GL_ARRAY_BUFFER, sizeof (glm::vec2) * 100 , &translations[0 ], GL_STATIC_DRAW);glBindBuffer (GL_ARRAY_BUFFER, 0 ); glEnableVertexAttribArray (2 );glBindBuffer (GL_ARRAY_BUFFER, instanceVBO);glVertexAttribPointer (2 , 2 , GL_FLOAT, GL_FALSE, 2 * sizeof (float ), (void *)0 );glBindBuffer (GL_ARRAY_BUFFER, 0 );glVertexAttribDivisor (2 , 1 );
仔细一看, 重点显然就是 glVertexAttribDivisor(2, 1);
了.
这个函数是用来指定 vertex attribute 的更新频率的. 其第一个参数是指定
"我们要指定哪一个 vertex attribute 的更新频率", 第二个参数是指定 "每几个
instance 更新一次该 vertex attribute". 如果设置为 0,
则为正常的逐顶点更新, 如果设置为 1, 则每 1 个 instance 更新一次,
以此类推.
这时候可以稍微想一下, 我们指定了 offset 每一个 instance 更新一次,
需不需要指定其他 vertex attribute 的更新频率呢? 在本例中,
一个显然的现象是: offset 是随 instance 改变的, 而其他 vertex attribute
我们都希望保持不变.
那么其实 glDrawArraysInstanced 已经为我们完成了这一步.
它不会去改变我们未指定为 instanced array 的 vertex attribute.
从这也可以逆过来知道: 被 glVertexAttribDivisor 影响的
vertex attribute 就会被判定为 instanced array.
至此基本就能用 instancing 做很多事情了, 最基本的就是将 model 矩阵逐
instance 改变, 我暂时也想不出其他用法. 另外, 一定要记得 VAO.
在上面的代码没有写出来.
Anti Aliasing (抗锯齿)
SSAA ( super sample
anti-aliasing )
超采样抗锯齿的原理是:
先将场景以比实际显示更高的分辨率渲染(比如原本是1920×1080, SSAA
可能会以3840×2160渲染), 在高分辨率下, 每个最终显示的像素对应多个采样点,
SSAA 会采集这些点的颜色信息, 然后将这些采样点的颜色取平均,
得到最终像素的颜色. 最后将处理后的图像缩小到实际屏幕分辨率显示.
上面的原理可能容易理解, 但在实现方面似乎并没有那么直接.
实际上, 以OpenGL为例, 为了实现 SSAA, 需要用到 fbo. 具体来说,
就是创建一张 fbo 的纹理附件, 这个纹理附件的分辨率要比窗口大. 渲染到 fbo
的时候正常渲染, 但是使用 glViewPort 将渲染的视口设定为与纹理附件一致.
然后渲染到默认 fbo 之前再次用 glViewPort 将视口调整为窗口大小.
(代码仅用作示意)
glBindFramebuffer (GL_FRAMEBUFFER, fbo);glViewport (0 , 0 , 3840 , 2160 );glClear (GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);renderScene ();glBindFramebuffer (GL_FRAMEBUFFER, 0 );glViewport (0 , 0 , 1920 , 1080 );glClear (GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);glUseProgram (yourShaderProgram);glActiveTexture (GL_TEXTURE0);glBindTexture (GL_TEXTURE_2D, texture);glUniform1i (glGetUniformLocation (yourShaderProgram, "textureSampler" ), 0 );glBindVertexArray (yourQuadVAO);glDrawArrays (GL_TRIANGLE_STRIP, 0 , 4 );glBindVertexArray (0 );
实际上在 cpp 文件中写好还没完, 在采样纹理附件的时候, 我们用的
fragment shader 也可以有一些操作空间. 在默认情况下, OpenGL
会把缩小的纹理附件自动用双线性插值完成缩小, 但是我们也可以在 fragment
shader 中自己完成插值操作.
#version 330 core in vec2 TexCoords; out vec4 FragColor; uniform sampler2D textureSampler; void main () vec2 texelSize = 1.0 / textureSize (textureSampler, 0 ); vec4 color = vec4 (0.0 ); color += texture (textureSampler, TexCoords + vec2 (-0.25 , -0.25 ) * texelSize); color += texture (textureSampler, TexCoords + vec2 (0.25 , -0.25 ) * texelSize); color += texture (textureSampler, TexCoords + vec2 (-0.25 , 0.25 ) * texelSize); color += texture (textureSampler, TexCoords + vec2 (0.25 , 0.25 ) * texelSize); color /= 4.0 ; FragColor = color; }
SSAA 的优点就是效果好, 最直白的大力出奇迹. 缺点也很明显,
就是对性能要求高.
MSAA (multisample
anti-aliasing)
原理是通过增加采样点, 对最终颜色进行加权计算得到结果.
一句话说下来是很简单, 不过细究下去就会有很多问题.
首先, fragment shader 的运行方式是怎样的?
是对每个被覆盖的子采样点都进行计算, 然后加权平均吗? 显然不可能是,
因为这样计算量太大了, 没什么用;
实际上, 不论有多少个子采样点, fragment shader 都只会运行一次,
它计算的时候使用的几何数据依旧来自当前 pixel 的中心点. MSAA
会使用一个更大的深度/模板缓冲来确定子采样点的覆盖范围,
而被覆盖的子采样点的数量决定当前 pixel 贡献给 framebuffer
的颜色有多少.
↑上面这句话算是对原文( LearnOpenGL )的一个翻译.
我个人对这句话依旧有一些不理解的东西. "MSAA
会使用一个更大的深度/模板缓冲来确定子采样点的覆盖范围" 这句话,
没有说明深度缓冲到底用来存什么数据. 问了 ds, 似乎就是子采样点的深度值,
没什么特殊的. 那就是说 MSAA 用子采样点的深度值来判断覆盖情况吗?
我就这样继续提问了.
到此算是完成对 MSAA 执行过程的一部分理解了, 即, MSAA
"如何判断子采样点覆盖情况" 的问题.
MSAA in OpenGL
如果想在 OpenGL 中使用 MSAA, 首先需要的就是一个能够在每个 pixel
存储"多于一个采样值" 的缓冲. (显然, 有别于我们平时正常的颜色缓冲,
深度缓冲等). 这种缓冲被称为多重采样缓冲 .
大部分窗口系统能够为我们提供多重采样缓冲, 比如我们使用的 GLFW.
glfwWindowHint (GLFW_SAMPLES, 4 );
现在, 我们屏幕上的每一个坐标都有四个子采样点, 这也意味着我们的 buffer
大小增加到四倍.
如果我们进行的渲染操作都只是写入 default framebuffer 的话,
只需要一句话就能让 OpenGL 启动多重采样抗锯齿.
glEnable (GL_MULTISAMPLE);
不过, 如果需要使用自己的 framebuffer, 那就要自行创建多重采样缓冲.
但不论如何, 对于 framebuffer, 我们只有两个选择: texture attachment 和
renderbuffer attachment. 而创建多重采样缓冲需要的操作也不多.
首先考虑 texture attachment . 相比之前,
需要更改一下使用的函数和传入的参数.
(代码仅作示意)
glBindTexture (GL_TEXTURE_2D, screenColorBuffer);glTexImage2D (GL_TEXTURE_2D, 0 , GL_RGB, RenderState::SCREEN_WIDTH, RenderState::SCREEN_HEIGHT, 0 , GL_RGB, GL_UNSIGNED_BYTE, NULL );glBindTexture (GL_TEXTURE_2D, 0 );glTexParameteri (GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);glTexParameteri (GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);glFramebufferTexture2D (GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, screenColorBuffer, 0 );glBindTexture (GL_TEXTURE_2D_MULTISAMPLE, screenColorBuffer);glTexImage2DMultisample (GL_TEXTURE_2D_MULTISAMPLE, RenderState::samplesNum, GL_RGB, RenderState::SCREEN_WIDTH, RenderState::SCREEN_HEIGHT, GL_TRUE);glBindTexture (GL_TEXTURE_2D_MULTISAMPLE, 0 );glFramebufferTexture2D (GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, screenColorBuffer, 0 );
(还有一个细节就是后者不需要指定环绕方式)
基本上就是多加一个"multisample". 这里区别比较大的是第二个函数, 用的是
glTexImage2DMultisample, 其最后一个参数如果传入
GL_TRUE, 那么 image 将会为每个 texel
使用相同的采样位置和相同数量的子采样点.
其次考虑 renderbuffer attachment .
(代码仅作示意)
glBindRenderbuffer (GL_RENDERBUFFER, rbo);glRenderbufferStorage (GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, width, height);glFramebufferRenderbuffer (GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);glBindRenderbuffer (GL_RENDERBUFFER, rbo);glRenderbufferStorageMultisample (GL_RENDERBUFFER, 4 , GL_DEPTH24_STENCIL8, width, height); glFramebufferRenderbuffer (GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
渲染至多重采样帧缓冲
通过刚才的步骤,
我们已经创建了多重采样帧缓冲(实际上就是将帧缓冲附件从正常版本改成多重采样版本).
后续要做的, 就是渲染至这个帧缓冲, 然后绘制其纹理附件. 前者是比较直接的,
直接渲染就好, 但是对于后者, 由于多重采样缓冲的特殊性,
我们无法直接用这些缓冲做别的事情, 比如在 shader 中采样它. 因此,
后者的实现还是需要一些操作的.
一个多重采样图像存储的信息远远多与一个正常的图像,
所以我们需要对图像进行 downscale(降采样) 或 resolve(解析).
解析一个多重采样图像一般通过 glBlitFramebuffer实现.
这个函数能够从一个帧缓冲拷贝一个区域到另一个帧缓冲中,
同时解析任何多重采样缓冲.
glBindFramebuffer (GL_READ_FRAMEBUFFER, multisampledFBO);glBindFramebuffer (GL_DRAW_FRAMEBUFFER, 0 );glBlitFramebuffer (0 , 0 , width, height, 0 , 0 , width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
绑定好读取和写入的帧缓冲, 然后传入四个坐标指定好要拷贝的区域. 现在,
就可以绘制纹理附件了.
这里要注意一下, 在我尝试在渲染器实现 MSAA 的时候发现, 我们
GL_DRAW_FRAMEBUFFER 传入的 fbo 必须是另外一个
fbo(至少我传入默认 fbo 时渲染不出来), 然后按照正常的绘制 fbo 的方式渲染.
这里直接看代码会更清晰.
if (RenderState::enableMSAA) { if (intermediateFBO == 0 ) { glGenFramebuffers (1 , &intermediateFBO); glBindFramebuffer (GL_FRAMEBUFFER, intermediateFBO); } if (msColorBuffer == 0 ) { glGenTextures (1 , &msColorBuffer); glBindTexture (GL_TEXTURE_2D, msColorBuffer); glTexImage2D (GL_TEXTURE_2D, 0 , GL_RGB, RenderState::SCREEN_WIDTH, RenderState::SCREEN_HEIGHT, 0 , GL_RGB, GL_UNSIGNED_BYTE, NULL ); glTexParameteri (GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri (GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glFramebufferTexture2D (GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, msColorBuffer, 0 ); } if (glCheckFramebufferStatus (GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE) std::cout << "ERROR::FRAMEBUFFER:: Intermediate framebuffer is not complete!" << std::endl; glBindFramebuffer (GL_FRAMEBUFFER, 0 ); glBindFramebuffer (GL_READ_FRAMEBUFFER, fbo); glBindFramebuffer (GL_DRAW_FRAMEBUFFER, intermediateFBO); glBlitFramebuffer (0 , 0 , RenderState::SCREEN_WIDTH, RenderState::SCREEN_HEIGHT, 0 , 0 , RenderState::SCREEN_WIDTH, RenderState::SCREEN_HEIGHT, GL_COLOR_BUFFER_BIT, GL_NEAREST); } glBindFramebuffer (GL_FRAMEBUFFER, 0 );glDisable (GL_DEPTH_TEST);glClearColor (1.0f , 1.0f , 1.0f , 1.0f );glClear (GL_COLOR_BUFFER_BIT);unsigned int & colorBuffer = RenderState::enableMSAA ? msColorBuffer : textureColorbuffer;shader->use (); glBindVertexArray (quadVAO);glBindTexture (GL_TEXTURE_2D, colorBuffer);glDrawArrays (GL_TRIANGLES, 0 , 6 );
需要注意的就是, 作为中介的 intermediateFBO 不需要创建 rbo.
它的作用就是将通过 blit 解析后的纹理附件提供给 shader 绘制.
梳理一下思路就是: 创建帧缓冲, 给帧缓冲添加多重采样的附件(包括 texture
attachment 和 renderbuffer attachment), 然后绑定至该帧缓冲, 正常渲染,
使用 blit 解析纹理附件到另一个中介 fbo, 然后绑定至默认帧缓冲, 为绘制
quad 的 shade 传递中介 fbo 的纹理附件对应的纹理, 绘制.
自定义抗锯齿算法
实际上多重采样的图像也是能够传递给 shader, 并被采样使用的.
uniform sampler2DMS screenTextureMS;
下面这个是检索特定屏幕坐标中某个特定的子采样点.
vec4 colorSample = texelFetch (screenTextureMS, TexCoords, 3 );
可以用这两个操作自己实现抗锯齿.
.jpg)